How to reserve cluster resources
| Description | How to reserve cluster resources |
|---|---|
| Related-course materials | Howtos cluster i-Trop |
| Authors | Julie Orjuela (julie.orjuela_AT_irf.fr), Christine Tranchant (christine.tranchant_AT_ird.fr) |
| Creation Date | 10/02/2022 |
| Last Modified Date | 15/07/2026 |
Summary
How to resource cluster resources ?
- 1. Who is working on the cluster ?
- 2. How to choose a adapted partition for my data analysis ?
- 3. Select the node to use
- 4. How to check /scratch space ?
- 5. Ressources summary
How to reserve cluster resources ?
If you start a new analysis, you wonder what partition, nodes and resources ( number of cpu and RAM memory) you need .
In this tutorial, you can find a survival to know how to reserve cluster resources.
1. Who is working on the cluster ?
First, check who is working on the cluster to have an overview of load cluster.
Using squeue command, you can observe jobs, users, partitions, state of every jobs and which nodes have been allocated to which jobs.
It can give you an idea of what nodes can be used or not.
orjuela@master0 ~]$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
983603 normal beast orjuela R 5:23:05 1 node20
983602 normal beast orjuela R 5:23:11 1 node20
983605 normal beast orjuela R 5:16:24 1 node20
983604 normal beast orjuela R 5:16:32 1 node20
983607 normal beast orjuela R 5:09:15 1 node20
983606 normal beast orjuela R 5:09:21 1 node20
983596 normal FlyeRave tando R 5:57:46 1 node20
983594 normal Unicycl_ tando R 5:11:57 1 node13
982965_71 normal range_r0 comte R 13:36 1 node18
982965_70 normal range_r0 comte R 15:01:36 1 node18
982965_69 normal range_r0 comte R 1-04:32:15 1 node18
982965_68 normal range_r0 comte R 1-07:58:54 1 node19
982965_67 normal range_r0 comte R 1-13:14:58 1 node19
982965_66 normal range_r0 comte R 1-22:58:13 1 node19squeue command has a lot of options, use -u option to check allocated resources to a user, in this case “totoro”, is waiting for resources but some jobs are running into node 18 and 19.
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
982965_[74-89] normal range_r0 totoro PD 0:00 1 (AssocGrpCpuLimit)
982965_73 normal range_r0 totoro R 1:28:27 1 node19
982965_72 normal range_r0 totoro R 3:31:51 1 node18
982965_71 normal range_r0 totoro R 5:59:55 1 node18
982965_70 normal range_r0 totoro R 20:47:55 1 node18
982965_69 normal range_r0 totoro R 1-10:18:34 1 node18
982965_68 normal range_r0 totoro R 1-13:45:13 1 node192. How to choose a adapted partition for my data analysis ?
Depending on the type of jobs (analysis), you can choose between different partitions.
The partitions are waiting lists, each with specific priorities and constraints such as the size, the time limit of a job or the users authorized to use it, etc.
In this table, we list differents partitions availables on our cluster and some details about RAM and CPU number.
| partition | role | nodes | Number of Cores | Ram on nodes | DefMemPerCPU | MaxMemPerCPU | |||
|---|---|---|---|---|---|---|---|---|---|
| short | Short Jobs < 1 day (higher priority,interactive jobs) | 3,14-16,18 |
12 to 64 cores | 64 to 144GB | 2,5GB | 5,3GB | |||
| normal | job of maximum 14 days | 0-1,4-5,7-9,11,17,20-21,24,27 | 20 to 88 cores | 64 to 256GB | 3GB | 8GB | |||
| long | 14 days< long jobs< 45 days | 10,12-13,22-23 | 12 to 20 cores | 48 to 64GB | 3GB | 5,3GB | |||
| highmem | jobs with more memory needs | 28,29,30 |
112 cores | 512GB | 4,5GB | 9GB | |||
| supermem | jobs with much more memory needs | node2,node25 | 40 to 256 cores | 1 to 2TB | 8GB | 25GB | |||
| gpu | Need of analyses on GPU cores | node26 | 24 cpu and 8 GPUS cores | 192 GB | 8GB | 8GB | global | Partition for the Global project | node31 | 112 cores | 512 GB | 4,5GB | 9GB |
2.1 Explanation of DefMemPerCPU and MaxMemPerCPU parameters:
DefMemPerCPU is the default amount of memory per cpu defined for the partitions.For exemple for the normal partition, when you reserve 1 core, 3G of RAM on the node is also reserved .
You can modify the amount of RAM per cpu according to the value of the parameter MaxMemPerCPU which is the maximum amount of RAM per CPU that can be chosen.
The value to set depends on the ratio amount of RAM/number of CPU of each node of the partition ( see the 5. Ressources summary for more details).
The option to use is --mem-per-cpu=XG with XG the mumber of GB per cpu wanted.
For exemple for the normal partition, the MaxMemPerCPU is 8GB that corresponds to the maximum value allowed for the node7.
The command to use for an interactive session is:
srun -p normal –mem-per-cpu=8G –pty bash -i
2.2 How do partitions work:
Jobs are prioritized and processed using the resources (CPU and RAM) of the nodes that make up these partitions.
-
By default, the chosen partition is the normal partition. On this partition, job are killed after 14 days !! Note that all the nodes of this partition are infiniband (more details here https://bioinfo.ird.fr/index.php/en/how-to-use-the-mutualized-scratch/)
-
If you need to test a command line or a script, use the short partition.
-
The highmem partition should only be used for jobs requiring at least 35-40GB of memory.
-
The supermem partition has to be used for large assemblies and jobs requiring more than 100GB of memory. Note that all the nodes of this partition are infiniband
-
The gpu partition is used for nanopore basecalling, polishing/correction and for machine learning algorithms.
The partition can be chosen following this scheme. But in a general way, check cpu number and memory needed by the tool you want to use.
Time estimation can be tricky, we recommended to seek for advice from the bioinformaticians in your UMR (error/experience balance !).
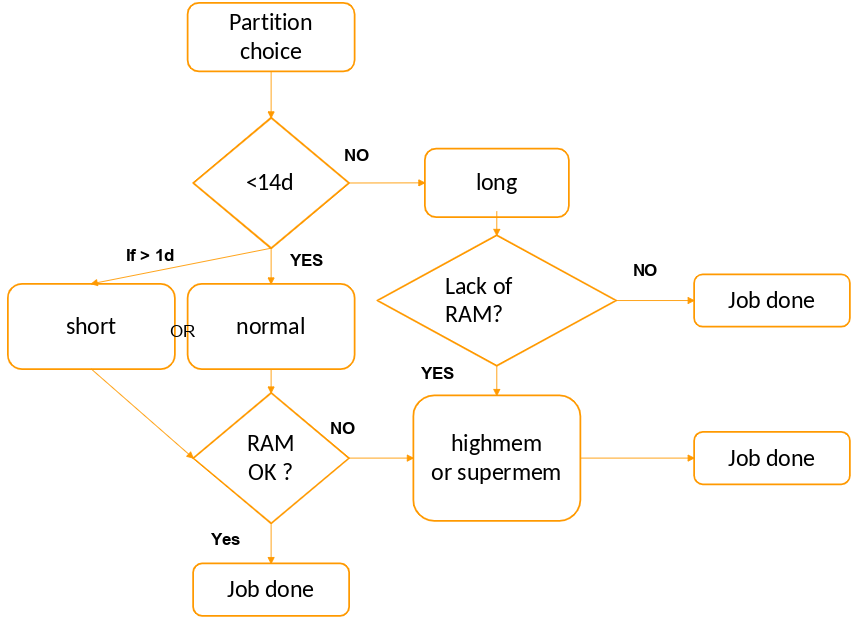
In below table, we put in some examples, with usecases to help you in the choice of partitions.
| Rules | Partition | Some tools | Comments |
|---|---|---|---|
| basecalling/demultiplexing/correction | gpu | medaka/guppy/machine learning tools | request for access to the necessary partition |
| assemblies >100G RAM | supermem | miniasm/flye/raven/smartdenovo | genome target > 400 Mb (riz genome assembly does not consume 100GB) |
| genomicsbd (gatk) > 100G RAM | supermem | GATK genomicsDB | genome target > 400 Mb (>10 samples) |
| assemblies => 35G et < 100G RAM | highmem | miniasm/flye/raven/smartdenovo | 100 Mb > genome target > 400 Mb |
| population genomics | long | ||
| simulations | long | ||
| metagenomics | normal | quiime2/frogs | |
| mapping | normal | bwa/minimap2/hisat2 | need a lot of cores but not a lot of RAM. It is necessary to reserve the number of cores that the tool will use. |
| genotyping | normal | GATK haplotypecaller/samtools mpileup/bcftools | need a lot of cores but not a lot of RAM. It is necessary to reserve the number of cores that the tool will use. |
| statistics | normal | R | |
| scripts debugging and test | short | bash/python/R |
In any case, to use a determinate partition, use the -p option (or --partition parameter) with the srun or sbatch command line, in which partition can be normal, long, supermem, highmem, highmemplus, or gpu.
sbatch -p partition
srun -p partition3. Select the node to use:
Once you have decided the partition to use, check the nodes occupation .
We recommand to use squeue to check allocated resources in this particular node. For example in node8.
[orjuela@master0 ~]$ squeue | grep 'node18' -
982965_72 normal range_r0 elie R 4:19:51 1 node18
982965_71 normal range_r0 elie R 6:47:55 1 node18
982965_70 normal range_r0 elie R 21:35:55 1 node18
982965_69 normal range_r0 elie R 1-11:06:34 1 node18
982965_65 normal range_r0 elie R 2-08:11:31 1 node18
982965_60 normal range_r0 elie R 2-19:40:38 1 node18
982965_57 normal range_r0 elie R 3-17:21:45 1 node18squeue command with more options can help you to ckeck cpu and mem allocated by user in the chosen node .
In this example, 4 threads per job has been reserved but RAM memory was not specified.
[orjuela@master0 ~]$ squeue -O jobID,name:40,partition,nodelist,NumCPUs,MinMemory,state,timeused | grep 'node18' -
983654 range_r0 normal node18 4 0 RUNNING 4:23:09
983634 range_r0 normal node18 4 0 RUNNING 6:51:13
983587 range_r0 normal node18 4 0 RUNNING 21:39:13
983538 range_r0 normal node18 4 0You can also go inside node and use the htop command to visualize the memory consumed by a process.
ssh node18
htop4. How to check /scratch space ?
If you have decided to work in a specific node, you also have to check /scratch occupation.
To check the percentage of occupation of the temporary repository /scratch on each node, use the df -h command line.
In the node8 for example the /scratch is ocupated to 1% from 13To.
Sys. de fichiers Taille Utilisé Dispo Uti% Monté sur
/dev/sda2 29G 8,8G 19G 33% /
devtmpfs 24G 0 24G 0% /dev
tmpfs 24G 0 24G 0% /dev/shm
tmpfs 24G 57M 24G 1% /run
tmpfs 24G 0 24G 0% /sys/fs/cgroup
/dev/sdb1 13T 734M 12T 1% /scratch
/dev/sda1 477M 145M 308M 32% /boot
/dev/sda5 257G 78M 244G 1% /tmp
nas3:/data3 66T 61T 4,9T 93% /data3
nas2:/data 44T 41T 3,3T 93% /data
nas:/home 5,9T 5,4T 546G 91% /home
nas:/teams 5,0T 3,2T 1,9T 63% /teams
master0:/usr/local 2,5T 1,7T 824G 68% /usr/local
master0:/opt 50G 21G 30G 42% /opt
tmpfs 4,8G 0 4,8G 0% /run/user/0
nas:/data2 28T 25T 3,1T 89% /data2
tmpfs 4,8G 0 4,8G 0% /run/user/35449NOTE : In some nodes, check /tmp line percentage instead of /scratch.
NOTE : The nodes from the normal or supermem are infiniband and you can use the mutualized /scratch-ib instead of /scratch ( more details here: https://bioinfo.ird.fr/index.php/en/how-to-use-the-mutualized-scratch/).
5. Resources summary
You can find here a summary of nodes resources. You can find the node composition of each partition, the number of CPU available and the total RAM memory total of the node and its memory/cpu.
srun or sbatch arguments can be set easily with the --mem to reserve the total memory for a job.
For the --mem-per-cpu argument, you need to know how many Gb/cpu to use.
With this table, you know it all now !!
NOTE: New nodes specifications (in blue) can be found at the end of this table !! Check it out !
NEW AND IMPORTANT : Now you can use some nodes with infiniband to acelerate data transfert between san and nodes but also between nodes directly ! Don’t forget to use rsync with infiniband such as `rsync node0-ib:/scratch/user/data.txt node1-ib:/scratch/user/` … More details on https://bioinfo.ird.fr/index.php/en/tutorials-howtos-i-trop-cluster/
| NODELIST | PARTITION | CPUS | TOTAL MEMORY (Gb) | RAM PER CPU (Gb) | SCRATCH (To) | INFINIBAND |
|---|---|---|---|---|---|---|
| node0 | normal* | 24 | 144 | 6 | 13 | X |
| node1 | normal* | 24 | 144 | 6 | 1.8 | X |
| node2 | supermem | 256 | 2063 | 8 | 13 | X |
| node3 | short | 64 | 144 | 2.25 | 13 | |
| node4 | normal* | 72 | 257 | 4 | 13 | X |
| node5 | normal* | 88 | 515 | 6 | 13 | X |
| node7 | normal* | 48 | 385 | 8 | 13 | X |
| node8 | normal | 12 | 48 | 4 | 13 | X |
| node9 | normal* | 64 | 144 | 2.25 | 13 | X |
| node10 | long | 12 | 48 | 4 | 2.7 | |
| node11 | normal | 12 | 48 | 4 | 2.7 | X |
| node12 | long | 12 | 64 | 5 | 13 | |
| node13 | long | 12 | 64 | 5 | 13 | |
| node14 | short | 12 | 64 | 5 | 13 | |
| node15 | short | 12 | 64 | 5 | 2.5 | |
| node16 | short | 12 | 64 | 5 | 13 | |
| node17 | normal* | 48 | 144 | 3 | 13 | X |
| node18 | short | 12 | 64 | 5 | 2.5 | |
| node20 | normal* | 20 | 64 | 3 | 13 | X |
| node21 | normal* | 24 | 144 | 6 | 13 | X |
| node22 | long | 20 | 64 | 3 | 13 | |
| node23 | long | 20 | 64 | 3 | 13 | |
| node24 | normal* | 20 | 64 | 3 | 2.5 | X |
| node25 | supermem | 40 | 1030 | 26 | 2.5 | X |
| node26 | gpu | 24 | 192 | 8 | 13 | X |
| node27 | normal | 24 | 144 | 6 | 13 | X |
| node28 | highmem | 112 | 514 | 5 | 7 | |
| node29 | highmem | 112 | 514 | 5 | 7 | |
| node30 | highmem | 112 | 514 | 5 | 7 | |
| node31 | global | 112 | 514 | 5 | 7 |
All informations regarding a node can be also obtained with the scontrol or sinfo -Nl command line.
with scontrol …
[orjuela@node18 ~]$ scontrol show nodes node18
NodeName=node18 Arch=x86_64 CoresPerSocket=6
CPUAlloc=12 CPUTot=12 CPULoad=12.01
AvailableFeatures=(null)
ActiveFeatures=(null)
Gres=(null)
NodeAddr=node18 NodeHostName=node18
OS=Linux 3.10.0-693.11.6.el7.x86_64 #1 SMP Thu Jan 4 01:06:37 UTC 2018
RealMemory=64232 AllocMem=0 FreeMem=9361 Sockets=2 Boards=1
State=ALLOCATED ThreadsPerCore=1 TmpDisk=2700000 Weight=1 Owner=N/A MCS_label=N/A
Partitions=normal
BootTime=2021-03-17T16:07:03 SlurmdStartTime=2021-05-20T12:30:01
CfgTRES=cpu=12,mem=64232M,billing=12
AllocTRES=cpu=12
CapWatts=n/a
CurrentWatts=0 AveWatts=0
ExtSensorsJoules=n/s ExtSensorsWatts=0 ExtSensorsTemp=n/sor with sinfo …
[orjuela@node18 ~]$ sinfo -Nl
Thu Feb 10 23:40:09 2022
NODELIST NODES PARTITION STATE CPUS S:C:T MEMORY TMP_DISK WEIGHT AVAIL_FE REASON
node0 1 short idle 24 2:12:1 144786 1334989 1 (null) none
node0 1 normal* idle 24 2:12:1 144786 1334989 1 (null) none
node1 1 short idle 24 2:12:1 144786 1800000 1 (null) none
node1 1 normal* idle 24 2:12:1 144786 1800000 1 (null) none
...
node27 1 highmem idle 24 2:12:1 144785 1321002 1 (null) none
node28 1 highmemdell mixed 112 2:28:2 514258 7626760 1 (null) none
node29 1 highmemdell idle 112 2:28:2 514247 7626760 1 (null) none
node30 1 highmemdell idle 112 2:28:2 514258 7626760 1 (null) none
node31 1 global idle 112 2:28:2 514258 7626760 1 (null) none License
no64Select
